WeAudit
Overview
WeAudit is a research project focused on scaffolding both end-users and AI practitioners in the process of auditing generative AI systems.
This work addresses the critical need for more systematic and participatory approaches to AI auditing in an era of rapidly deployed generative AI systems.
In this project page, we present the WeAudit workflow, core features on WeAudit system, relevant research publications, broader impact, and acknowledgements. We hope this project can inspire more research and practice in user-engaged AI auditing and responsible AI development.
The WeAudit Workflow
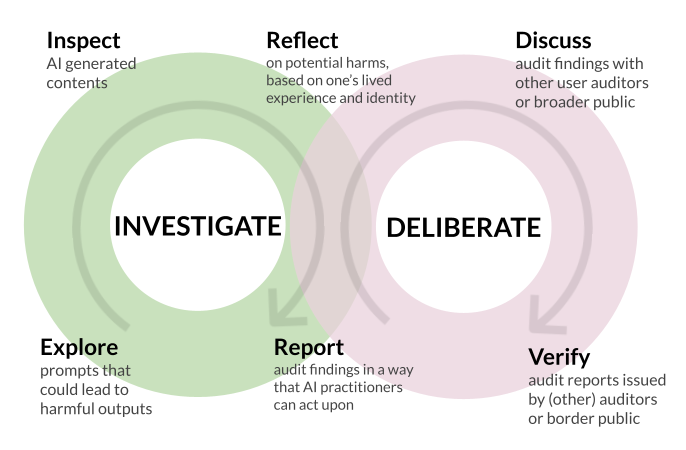
WeAudit organizes AI auditing into two intersecting, iterative loops designed to help both user auditors and AI practitioners collaborate in identifying and addressing potential harms in generative AI systems.
🔄 Investigate Loop
User auditors systematically explore prompts, inspect AI-generated outputs, and reflect on potential harms based on their unique experiences and identities.
- Explore: Try different prompts to find potentially harmful outputs
- Inspect: Review and compare the AI-generated results
- Reflect: Think about potential biases and harms based on personal knowledge
- Report: Document findings and potential harms
💬 Deliberate Loop
Auditors discuss findings with the community, leveraging diverse perspectives for a holistic understanding of AI-related harms.
- Discuss: Share and collaborate on audit findings with other users
- Verify: Confirm whether observations are perceived as harmful by multiple people
These loops are iterative and interconnected—new insights from discussion or verification may inspire further investigations.
WeAudit Core Features
Click on any feature to learn more:
Purpose: Support users in inspecting and comparing text-to-image (T2I) outputs and reflecting on potential harms.
How it works: Users can switch between single-prompt and pairwise comparison modes to examine how small variations in prompts affect the AI-generated images. This helps identify critical features and biases more easily.
Why it matters: Research shows that contrasting outputs helps users identify features they might otherwise miss. Expert audits have found that small wording changes in prompts can significantly shift the distribution of outputs in ways that reflect social biases.
Purpose: Capture and display all of a user's prior prompt explorations for easy access and continuation.
How it works: A sidebar displays the history of all prompts users have tested, along with the AI-generated images. Users can click entries to review past results or retrieve prompts to continue exploring variations.
Why it matters: Users in formative studies expressed the need to track their exploration journey. Easy access to prior explorations helps users build on their insights and identify patterns across multiple tests.
Purpose: Provide scaffolding through diverse audit examples from expert evaluations of T2I systems, helping users discover potential harms.
How it works: Users can click "Prompt Examples for Inspiration" to view 3 randomly-selected examples. Each example includes:
- Example prompts and AI-generated images
- A rationale explaining why the outputs could be harmful to certain groups
- Encouragement to think of similar harms based on personal experience and identity
Smart selection: The system uses a heuristic algorithm to prioritize showing examples with tags different from audits the user has already submitted, increasing diversity of explored topics.
Purpose: Show aggregated audit activity to encourage users to explore underexplored areas and contribute diverse perspectives.
How it works: Users can view a distribution of "affected groups" (e.g., religion, gender) and "types of harms" (e.g., stereotyping, economic loss) that other auditors have reported. The interface highlights what has been "most explored" and what is "underexplored." Users can click tags to view specific audit reports related to those areas.
Why it matters: Research shows that seeing other users' activities influences motivation and strategy. By highlighting underexplored areas, WeAudit encourages users to contribute unique perspectives based on their own identities and experiences.
Purpose: Guide users in creating structured, actionable audit reports that are useful for AI practitioners.
How it works: When users find a potentially harmful behavior, they submit a report following these steps:
- Observe: "Can you say more about what you observed?"
- Analyze: "Why do you think this could be harmful, and to whom?"
- Tag: Label the "type of harm" and "affected group(s)"
- Envision: "What would the AI outputs look like if the issues were fixed?" (Provides insight into what users found problematic)
- Context: Add optional comments, indicate if content is violent, and note relevance to personal identity or communities
- Highlight: Optionally mark the most relevant images with yellow boxes
Design insight: This structure is based on formative studies with industry practitioners and draws from crowdsourcing best practices for structured elicitation.
Purpose: Enable community discussion and collaboration around audit findings.
How it works: All audit reports are posted to a discussion forum in blog-post style. Users can:
- View other users' audit reports
- Post comments to discuss audit findings
- Filter reports by tags to explore specific harm types or affected groups
Anonymization: User identities are anonymized to protect privacy while enabling discussion.
Purpose: Assess whether identified harms are recognized by multiple people and ensure report quality.
How it works: Other users verify audit reports using a structured survey with four criteria:
- Clarity: Is the report written clearly and understandably?
- Harmfulness: Can reviewers understand why the reporter found this AI behavior harmful?
- Specificity: If disagreement, identify the reason: poorly written, unclear reasoning, or mismatch with images
- Reasonableness: Does the reported harm make sense?
Deployment flexibility: Verification can be conducted by a broader audience (as in research studies) or by the same community of auditors in full deployment.

Research Publications
WeAudit: Scaffolding User Auditors and AI Practitioners in Auditing Generative AI
CSCW 2025 ●
Best Paper Award ●
PAPER
Investigating Youth AI Auditing
FAccT 2025 ●
PAPER
Investigating What Factors Influence Users’ Detection of Harmful Algorithmic Bias and Discrimination.
HCOMP 2024 ●
Best Paper Award ●
PAPER
Understanding Practices, Challenges, and Opportunities for User-Engaged Algorithm Auditing in Industry Practice
CHI 2023 ●
PAPER ●
VIDEO
Broader Impact
WeAudit has been featured as educational materials for more than 800 students across 15 classes at CMU. The project has also inspired and informed AI safety and responsible AI efforts at multiple companies, including OpenAI, Microsoft, Google, and eBay. WeAudit project has been invited to give talks at Apple's Human-Centered Machine Learning team, Zhejiang University, and the Participatory AI Research & Practice Symposium.
Acknowledgements
WeAudit was generously supported by the National Science Foundation (NSF) Fairness in AI program in collaboration with Amazon under Award No. IIS-2040942, a Google Research Scholar Award, Carnegie Mellon University’s Block Center for Technology and Society, the Notre Dame–IBM Technology Ethics Lab, and the Microsoft AI and Society Fellowship program.